Working with Paycheck Protection Program data in R
In this post, I walk through the process of reading in the data from the Paycheck Protection Program, and show some basic analyses that can be done.
Load packages and set up environment:
library(tidyverse)
library(sf)
library(tigris)
library(lubridate)
library(janitor)
library(hrbrthemes)
theme_set(theme_ipsum(base_size = 18))
options(scipen = 999, digits = 4, tigris_use_cache = TRUE)Load and clean data
The data is available at this site: https://home.treasury.gov/policy-issues/cares-act/assistance-for-small-businesses/sba-paycheck-protection-program-loan-level-data
The data exists in numerous CSV files, separated by state and sometimes loan amount.
This code chunk identifies all the CSV files in the folder, reads them in, and combines them.
path <- "data/ppp"
#find all files in the folder that end in .csv
ppp <- list.files(path, full.names = TRUE, recursive = TRUE) %>%
keep(str_detect(., ".csv$")) %>%
#read each file with read_csv and combine them
set_names() %>%
map_dfr(read_csv, col_types = cols(.default = "c"), .id = "file_name") %>%
clean_names()
glimpse(ppp)## Rows: 4,885,388
## Columns: 18
## $ file_name <chr> "data/ppp/All Data by State/150k plus/foia_150k_plus.c…
## $ loan_range <chr> "a $5-10 million", "a $5-10 million", "a $5-10 million…
## $ business_name <chr> "ARCTIC SLOPE NATIVE ASSOCIATION, LTD.", "CRUZ CONSTRU…
## $ address <chr> "7000 Uula St", "7000 East Palmer Wasilla Hwy", "2606 …
## $ city <chr> "BARROW", "PALMER", "ANCHORAGE", "ANCHORAGE", "PALMER"…
## $ state <chr> "AK", "AK", "AK", "AK", "AK", "AK", "AK", "AK", "AK", …
## $ zip <chr> "99723", "99645", "99503", "99515", "99645", "99503", …
## $ naics_code <chr> "813920", "238190", "722310", "621111", "517311", "541…
## $ business_type <chr> "Non-Profit Organization", "Subchapter S Corporation",…
## $ race_ethnicity <chr> "Unanswered", "Unanswered", "Unanswered", "Unanswered"…
## $ gender <chr> "Unanswered", "Unanswered", "Unanswered", "Unanswered"…
## $ veteran <chr> "Unanswered", "Unanswered", "Unanswered", "Unanswered"…
## $ non_profit <chr> "Y", NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ jobs_retained <chr> "295", "215", "367", "0", "267", "231", "298", "439", …
## $ date_approved <chr> "04/14/2020", "04/15/2020", "04/11/2020", "04/29/2020"…
## $ lender <chr> "National Cooperative Bank, National Association", "Fi…
## $ cd <chr> "AK - 00", "AK - 00", "AK - 00", "AK - 00", "AK - 00",…
## $ loan_amount <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…This changes how the columns are interpreted, and separates the congressional district column into state and district. If the district value is blank, I replace it with NA.
ppp <- ppp %>%
mutate(jobs_retained = as.numeric(jobs_retained),
date_approved = mdy(date_approved),
loan_amount = as.numeric(loan_amount),
file_name = str_remove(file_name, path)) %>%
#separate cd column into state_2 and district
separate(cd, into = c("state_2", "district"), remove = FALSE) %>%
#when district is blank, replace with NA
mutate(district = case_when(district == "" ~ NA_character_,
district != "" ~ district)) %>%
mutate(loan_range = str_trim(loan_range),
loan_range = str_sub(loan_range, 3, str_length(loan_range)),
loan_range = case_when(!str_detect(file_name, "150k plus") ~ "Under $150k",
TRUE ~ loan_range))There are cases where the value in the state column doesn’t match the state embedded in the congressional district cd column.
#preview data where state doesn't match congressional district
ppp %>%
filter(file_name == "/All Data by State/Virginia/foia_up_to_150k_VA.csv") %>%
count(file_name, state, cd, state_2, sort = TRUE) %>%
mutate(flag_match = state == state_2) %>%
filter(flag_match == FALSE) %>%
slice(1:5)## # A tibble: 5 x 6
## file_name state cd state_2 n flag_match
## <chr> <chr> <chr> <chr> <int> <lgl>
## 1 /All Data by State/Virginia/foia_up_to_… VA GA - … GA 1 FALSE
## 2 /All Data by State/Virginia/foia_up_to_… VA MD - … MD 1 FALSE
## 3 /All Data by State/Virginia/foia_up_to_… VA NC - … NC 1 FALSE
## 4 /All Data by State/Virginia/foia_up_to_… VA PA - … PA 1 FALSE
## 5 /All Data by State/Virginia/foia_up_to_… VA WV - … WV 1 FALSEThere are only 414 rows where this occurs, and it is less than 1% of the dataset.
#summarize cases where mismatch occurs
ppp %>%
mutate(flag_match = state == state_2) %>%
count(flag_match) %>%
mutate(pct_mismatch = n / sum(n),
pct_mismatch = round(pct_mismatch, 4)) %>%
filter(flag_match == FALSE) %>%
arrange(-pct_mismatch)## # A tibble: 1 x 3
## flag_match n pct_mismatch
## <lgl> <int> <dbl>
## 1 FALSE 414 0.0001Most of these bad rows are in the foia_up_to_150k_other.csv and foia_150k_plus.csv files.
ppp %>%
mutate(flag_match = state == state_2) %>%
count(file_name, flag_match) %>%
group_by(file_name) %>%
mutate(pct_mismatch = n / sum(n),
pct_mismatch = round(pct_mismatch, 4)) %>%
ungroup() %>%
filter(flag_match == FALSE) %>%
arrange(-pct_mismatch) %>%
slice(1:5)## # A tibble: 5 x 4
## file_name flag_match n pct_mismatch
## <chr> <lgl> <int> <dbl>
## 1 /All Data by State/Other/foia_up_to_150k_other.… FALSE 195 0.995
## 2 /All Data by State/Virgin Islands/foia_up_to_15… FALSE 1 0.000600
## 3 /All Data by State/150k plus/foia_150k_plus.csv FALSE 112 0.0002
## 4 /All Data by State/Arkansas/foia_up_to_150k_AR.… FALSE 8 0.0002
## 5 /All Data by State/Kentucky/foia_up_to_150k_KY.… FALSE 10 0.0002I filter out the rows where the state doesn’t match the congressional district.
ppp <- ppp %>%
filter(state == state_2)This shows that there are some negative values in loan_amount. I filter out those values.
ppp %>%
mutate(loan_type = loan_amount > 0) %>%
count(loan_type)## # A tibble: 3 x 2
## loan_type n
## <lgl> <int>
## 1 FALSE 27
## 2 TRUE 4223841
## 3 NA 661106ppp <- ppp %>%
filter(loan_amount > 0 | is.na(loan_amount))Analysis
Loan amount
The first step is to split the data into 2 buckets. For loans above $150k, the SBA binned the loan amount instead of reporting the actual value.
ppp_under_150 <- ppp %>%
filter(!str_detect(file_name, "150k plus"))
ppp_over_150 <- ppp %>%
filter(str_detect(file_name, "150k plus")) %>%
mutate(loan_range = fct_infreq(loan_range))Among loans less than 150k, most are less than 21k, and the distribution is very heavily skewed to the right.
quantiles <- ppp_under_150 %>%
summarize(quantiles = quantile(loan_amount, probs = c(.25, .50, .75)),
probability = c("25th", "50th", "75th")) %>%
mutate(probability = as.factor(probability))
ppp_under_150 %>%
ggplot(aes(loan_amount)) +
geom_histogram() +
geom_vline(data = quantiles, aes(xintercept = quantiles, color = probability)) +
scale_y_comma() +
scale_x_comma(labels = scales::dollar) +
labs(title = "SBA PPP Loans",
subtitle = "Among loans less than $150k",
x = "Loan amount",
y = "Number of loans",
color = "Quantile")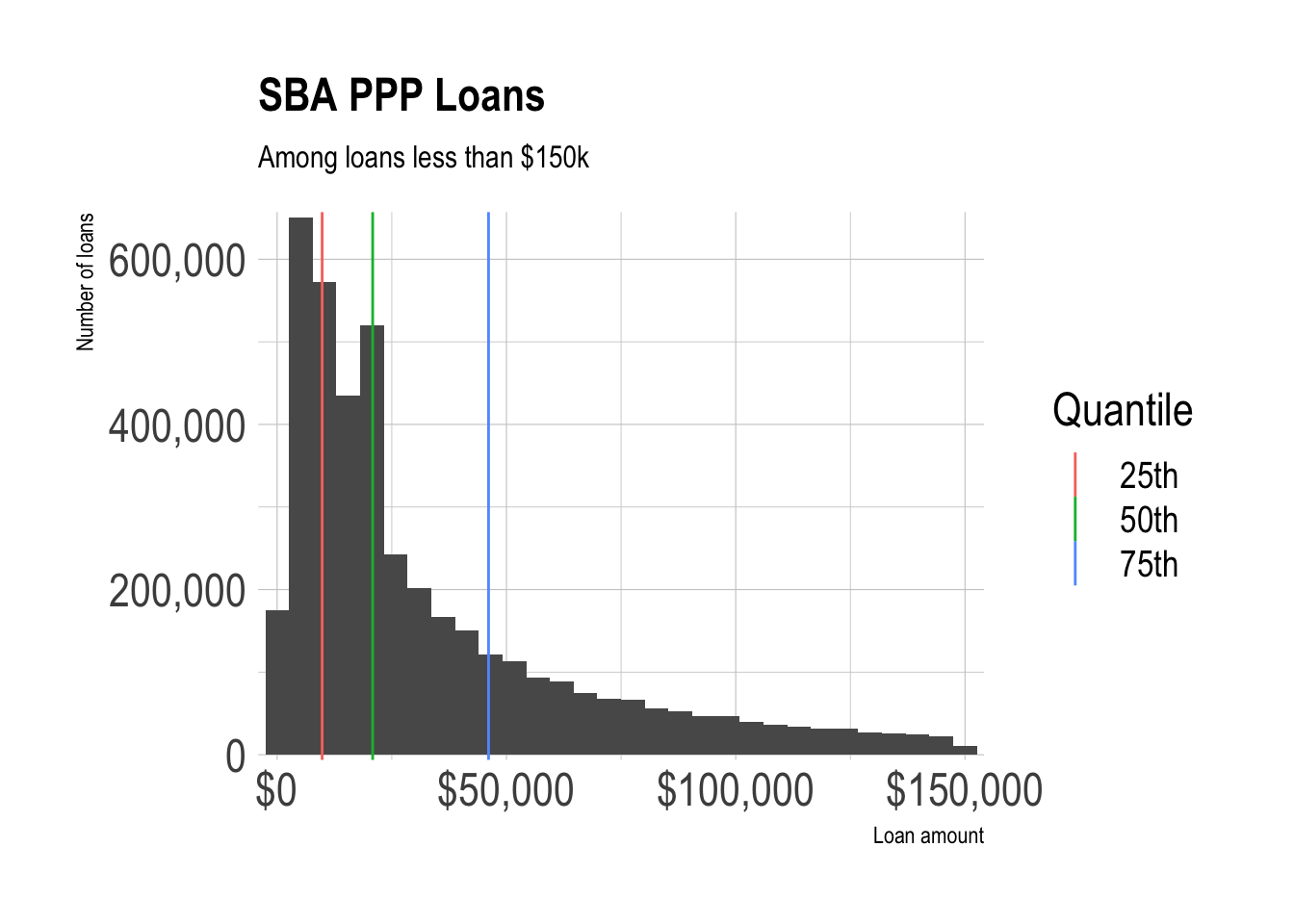
Loans under $150k make up the vast majority of all PPP loans.
ppp %>%
count(loan_range) %>%
mutate(loan_range = fct_reorder(loan_range, n)) %>%
ggplot(aes(n, loan_range)) +
geom_col() +
labs(title = "SBA PPP Loans",
subtitle = "All loans",
x = "Number of loans",
y = "Loan range") +
scale_x_comma()
Loan approvals peaked in late April 2020 when the program began accepting applications for the second round, and picked up in July. There is extreme weekday-weekend seasonality in the data after April. The “U” shape from May to July generally coincides with the effort to “reopen” economies nationwide.
ppp %>%
count(date_approved) %>%
ggplot(aes(date_approved, n)) +
geom_point() +
geom_vline(xintercept = ymd("2020-04-16"), linetype = 2) +
labs(title = "SBA PPP Loans",
x = NULL,
y = "Number of loans") +
scale_y_comma()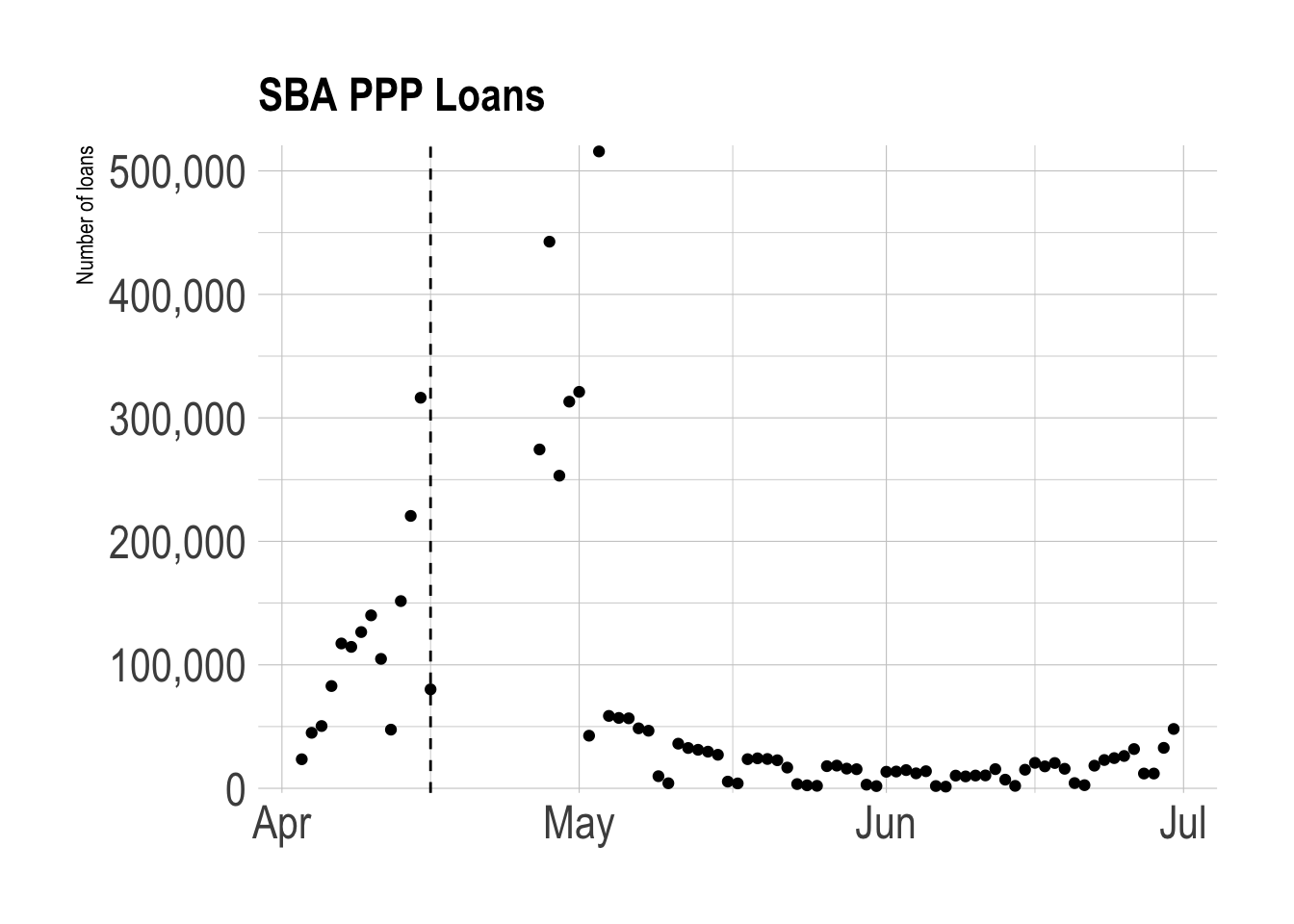
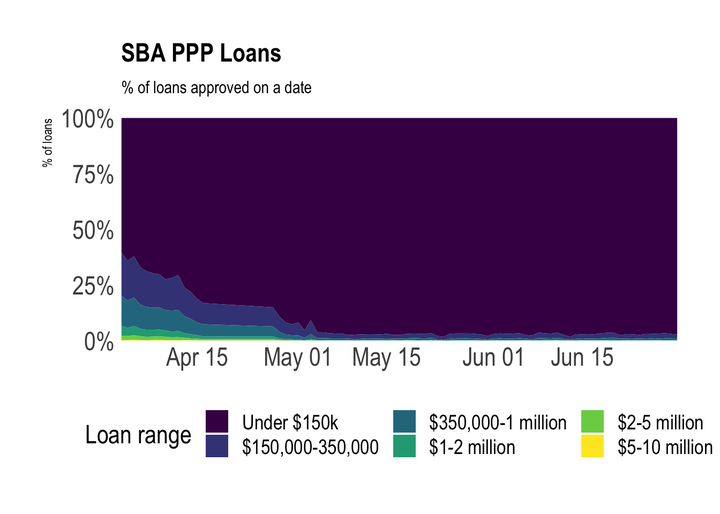
This shows that bigger loans tended to be approved earlier in the program, which was a major criticism.
ppp %>%
count(date_approved, loan_range) %>%
mutate(loan_range = fct_reorder(loan_range, n) %>% fct_rev) %>%
group_by(date_approved) %>%
mutate(pct_of_loans = n / sum(n)) %>%
ungroup() %>%
ggplot(aes(date_approved, pct_of_loans, fill = loan_range)) +
geom_area() +
scale_x_date(expand = c(0,0)) +
scale_y_percent(expand = c(0,0)) +
scale_fill_viridis_d() +
labs(title = "SBA PPP Loans",
subtitle = "% of loans approved on a date",
x = NULL,
y = "% of loans",
fill = "Loan range") +
theme(legend.position = "bottom")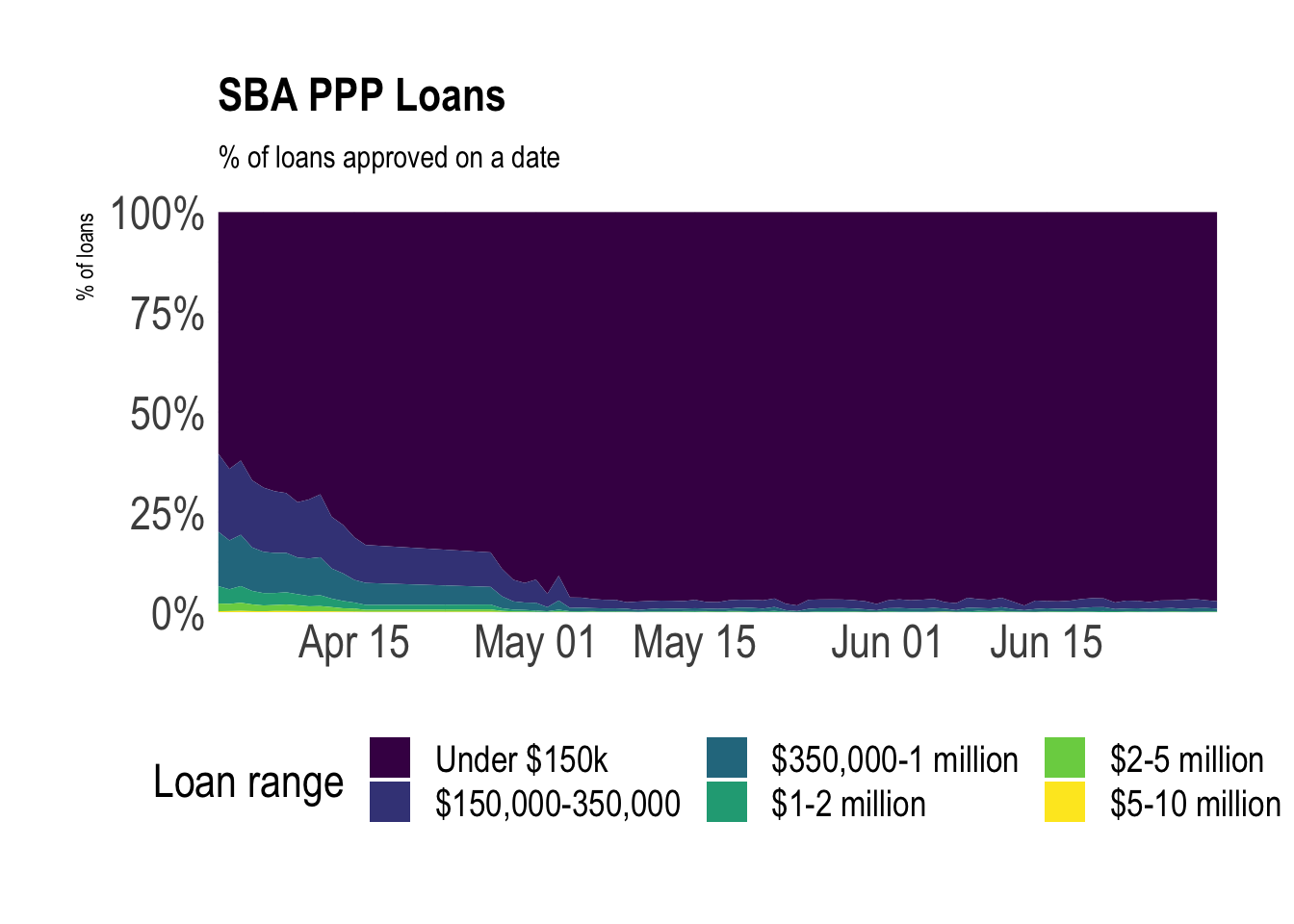
Most states received similar proportions of small and large loans. Territories received more small loans and fewer large loans.
ppp %>%
mutate(loan_range = fct_inorder(loan_range)) %>%
count(state, loan_range) %>%
group_by(state) %>%
mutate(pct_of_loans = n / sum(n)) %>%
ungroup() %>%
filter(!is.na(state)) %>%
mutate(state = fct_reorder(state, n, .fun = sum)) %>%
ggplot(aes(pct_of_loans, state, fill = loan_range)) +
geom_col() +
scale_fill_viridis_d(direction = -1) +
scale_x_percent() +
labs(title = "SBA PPP Loans",
subtitle = "% of loan range by state",
x = "% of loans",
y = NULL,
fill = "Loan range") +
theme(legend.position = "bottom")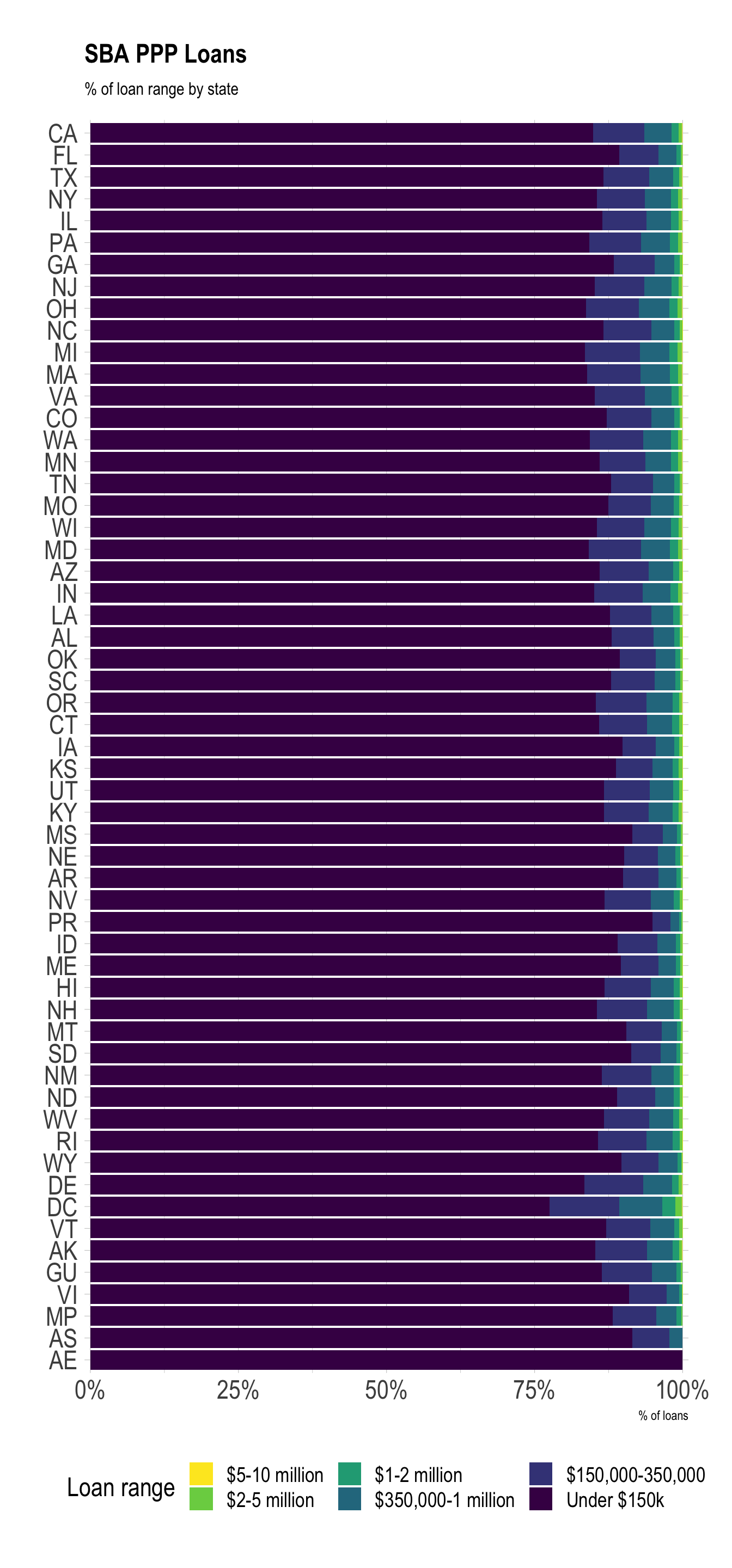
Jobs
Bigger loans tended to retain more jobs.
ppp %>%
filter(!is.na(jobs_retained)) %>%
mutate(loan_range = fct_inorder(loan_range) %>% fct_rev()) %>%
ggplot(aes(jobs_retained, fill = loan_range)) +
#geom_histogram(bins = 200) +
geom_density() +
facet_wrap(~loan_range, ncol = 2, scales = "free") +
scale_x_comma() +
#scale_y_comma() +
scale_fill_viridis_d() +
labs(title = "SBA PPP Loan Program",
subtitle = "Jobs retained",
x = "Number of jobs retained",
y = "Density",
fill = "Loan range")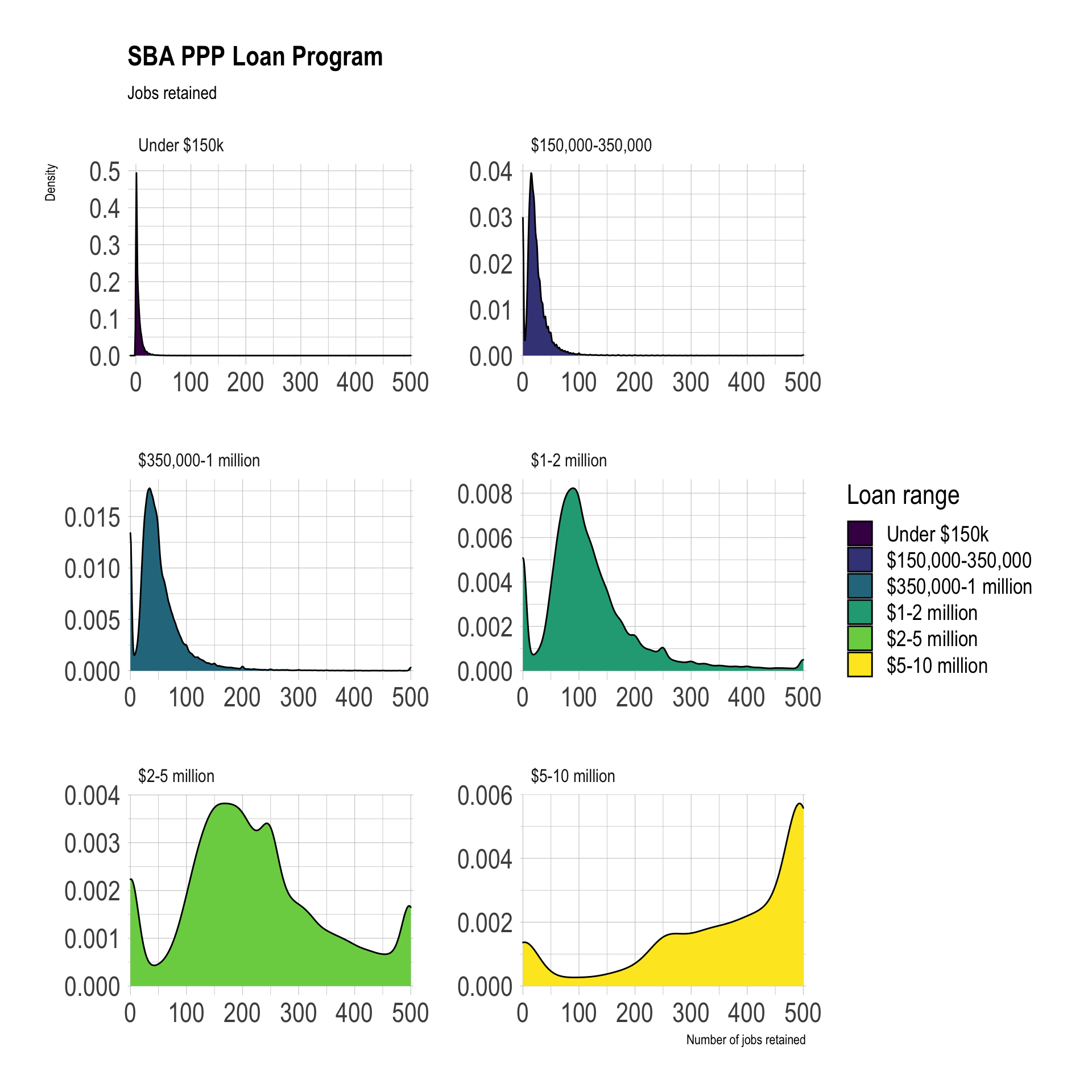
The timeline of jobs_retained closely matches the trend of when loans were approved.
ppp %>%
filter(!is.na(jobs_retained)) %>%
group_by(date_approved) %>%
summarize(jobs_retained = sum(jobs_retained)) %>%
ungroup() %>%
ggplot(aes(date_approved, jobs_retained)) +
geom_point() +
scale_y_comma() +
labs(title = "SBA PPP Loan Program",
subtitle = "Jobs Retained",
x = NULL,
y = "Jobs retained")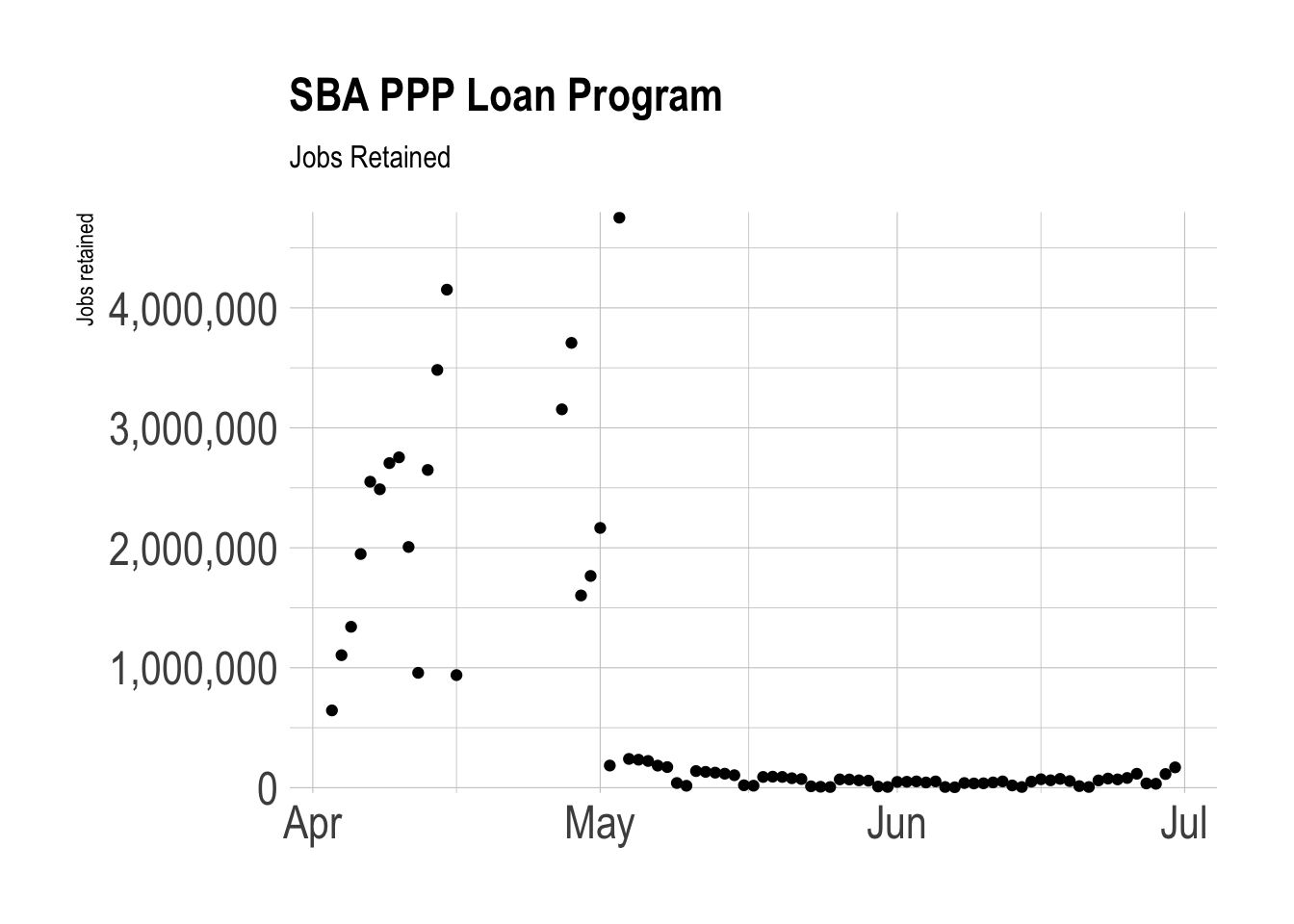
Among loans less than 150k and where the data was reported, the median loan retained 6 jobs per 50k spent. Systemic reporting bias probably makes this number less reliable.
ppp %>%
filter(loan_range == "Under $150k",
!is.na(jobs_retained),
!is.na(loan_amount)) %>%
select(jobs_retained, loan_amount) %>%
mutate(jobs_retained_per_50k = (jobs_retained / loan_amount) * 50000) %>%
summarize(jobs_retained_per_50k = median(jobs_retained_per_50k))## # A tibble: 1 x 1
## jobs_retained_per_50k
## <dbl>
## 1 6.21In the same loan range, bigger loans generally meant more jobs retained.
test <- ppp %>%
filter(loan_range == "Under $150k") %>%
count(loan_amount, jobs_retained, sort = TRUE) %>%
slice(1:5000)
test %>%
ggplot(aes(loan_amount, jobs_retained, color = n)) +
geom_density_2d_filled() +
scale_x_comma(labels = scales::dollar) +
labs(title = "SBA PPP Loan Program",
subtitle = NULL,
x = "Loan amount",
y = "Jobs retained",
fill = "Density of observations")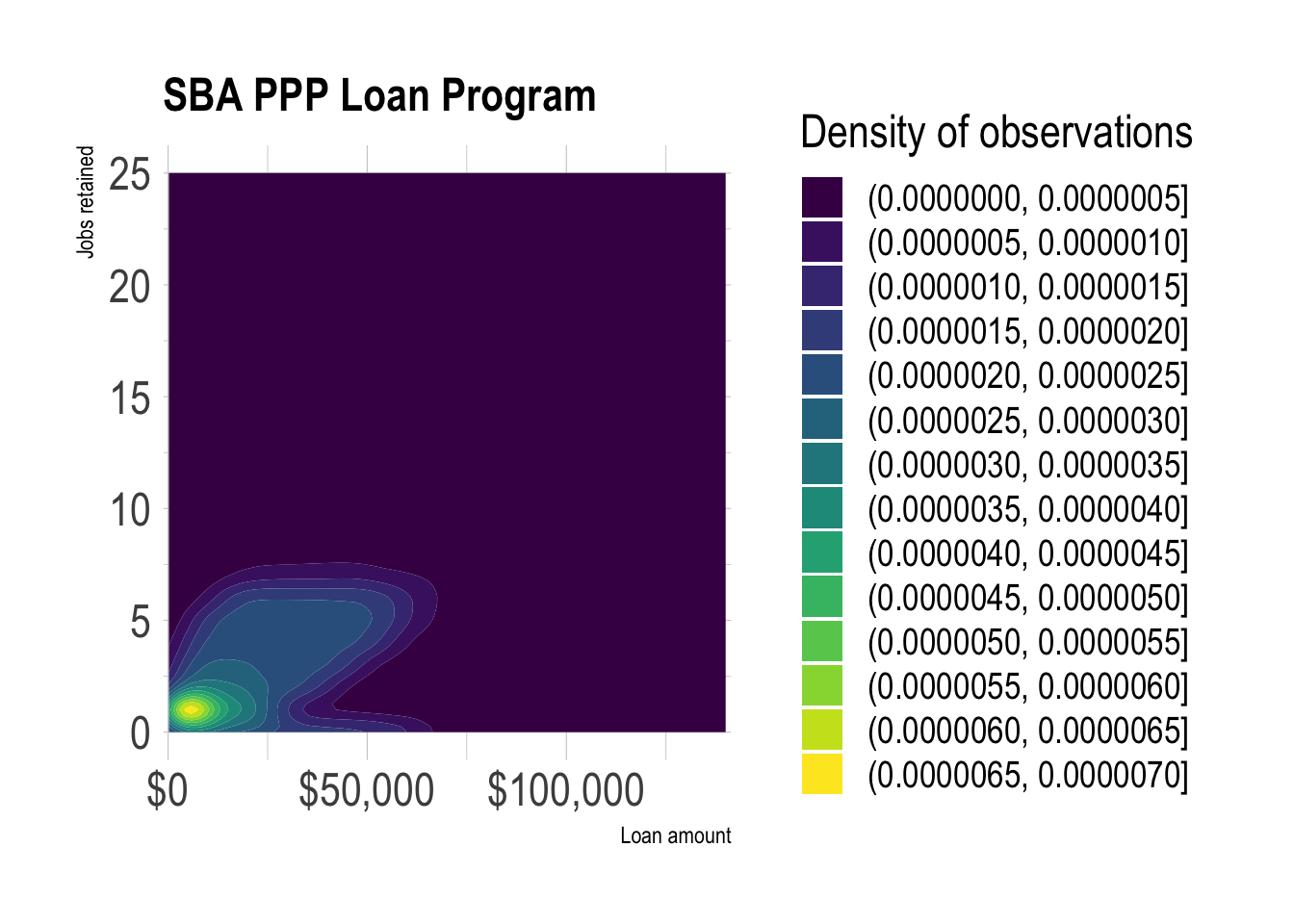
Mapping the data
The dataset identifies which federal congressional district the applicant is from. I use tigris to retrieve the shapefiles for the most recent districts.
congress_districts <- suppressMessages(congressional_districts(cb = TRUE, resolution = "500k", year = 2018)) %>%
st_as_sf() %>%
clean_names() %>%
filter(statefp == 42)This counts how many of each loan_range a district received. Note that there are missing values and what appear to be defunct district IDs in the district column.
ppp_pa_districts_loan_range <- ppp %>%
filter(state == "PA") %>%
count(district, loan_range, sort = TRUE)
ppp_pa_districts_loan_range %>%
mutate(district = fct_explicit_na(district),
district = fct_reorder(district, n, .fun = sum),
loan_range = fct_rev(loan_range)) %>%
ggplot(aes(n, district, fill = loan_range)) +
geom_col() +
scale_x_comma() +
scale_fill_viridis_d() +
labs(title = "SBA PPP Loan Program",
subtitle = "Pennsylvania",
x = "Number of loans",
y = "Congressional District",
fill = "Loan range")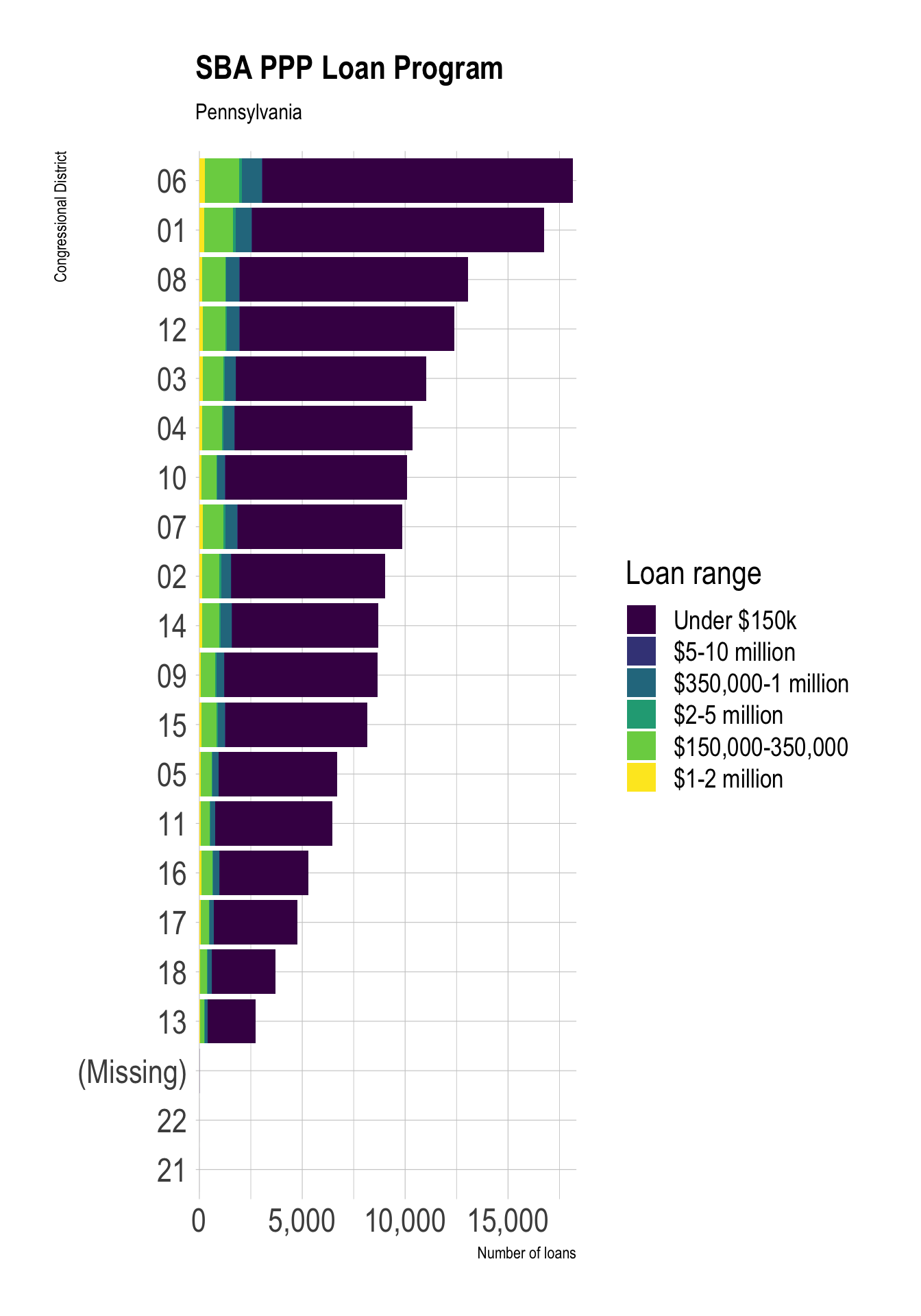
Districts in eastern Pennsylvania near Philadelphia received more loans from the program.
ppp_pa_districts <- ppp %>%
filter(state == "PA") %>%
count(district, sort = TRUE)
congress_districts %>%
right_join(ppp_pa_districts, by = c("cd116fp" = "district")) %>%
ggplot() +
geom_sf(aes(fill = n)) +
scale_fill_viridis_c(option = "A", labels = scales::comma) +
labs(title = "SBA PPP Loan Program",
subtitle = "Pennsylvania",
fill = "Number of loans") +
theme_void()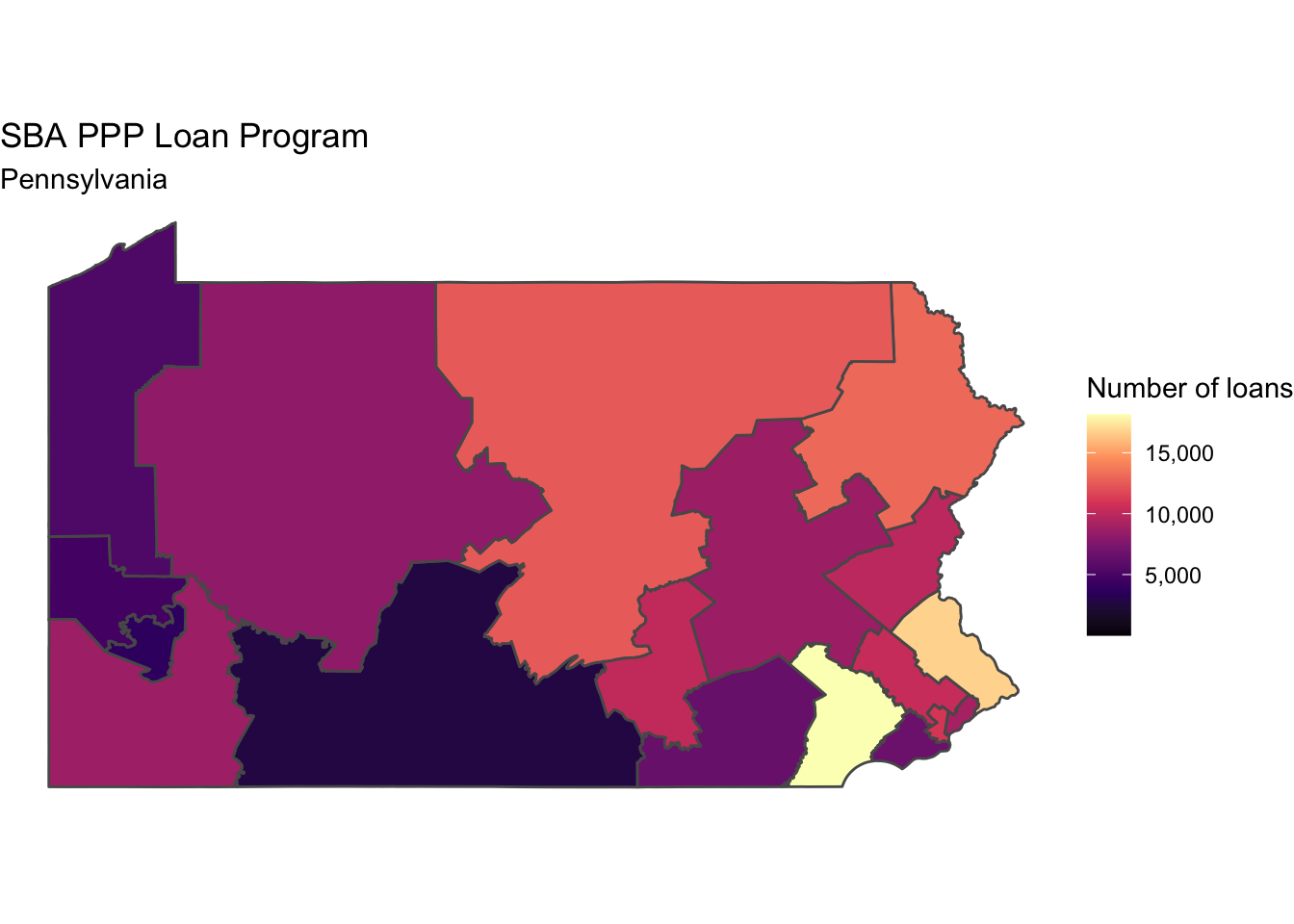
Conor Tompkins
Data scientist in the Pittsburgh area with an interest in data visualization, statistical programming, and civic data.