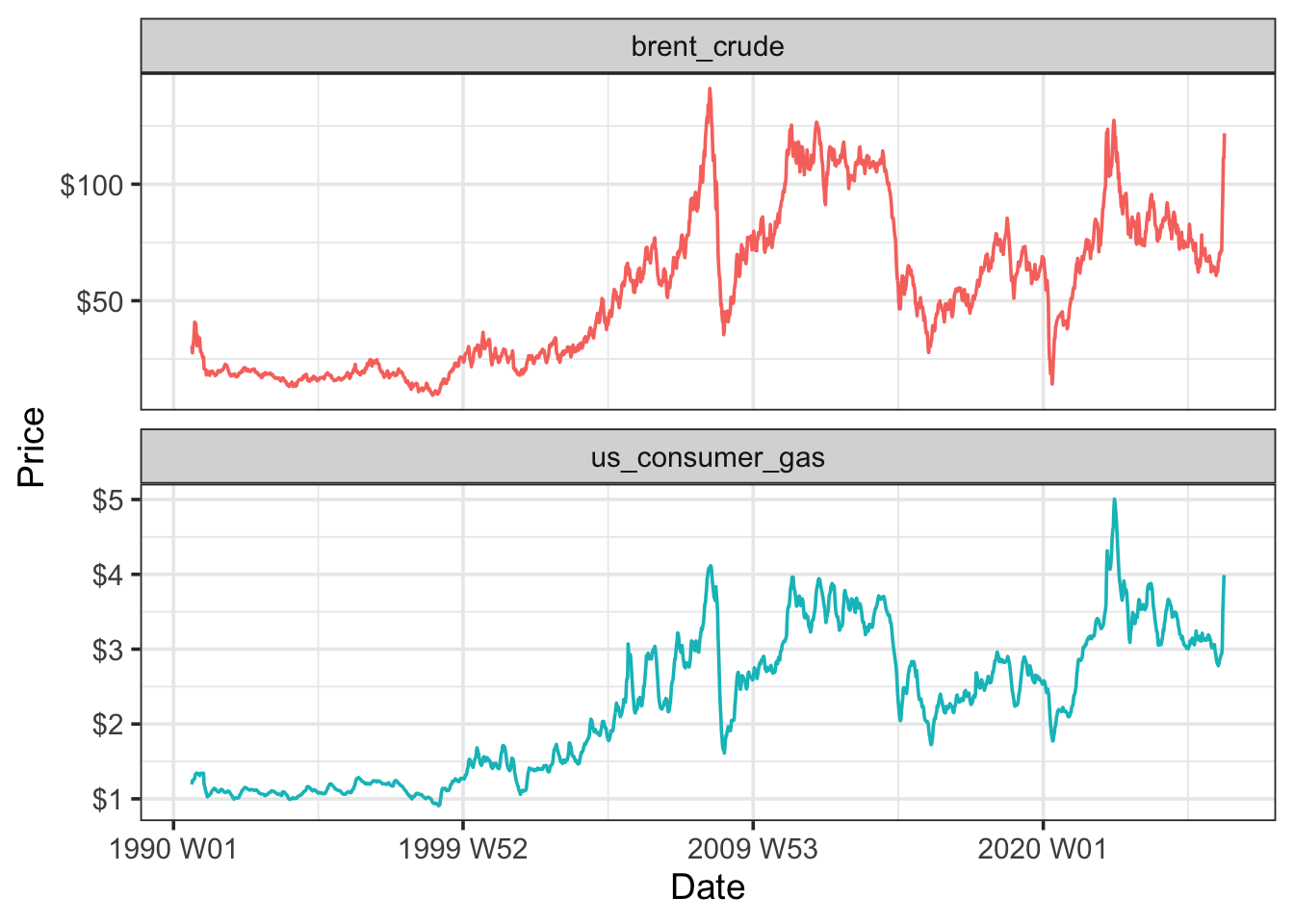
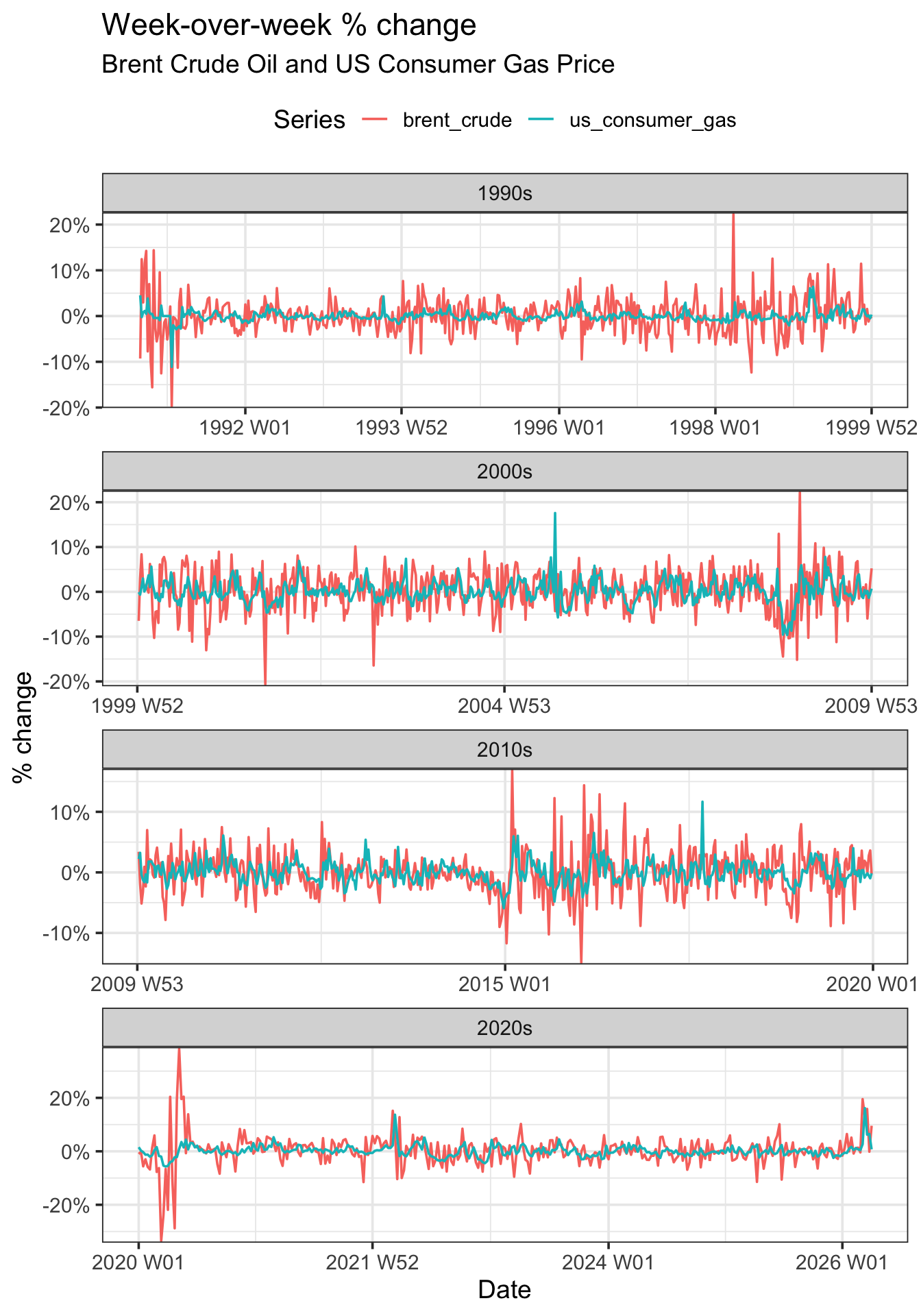
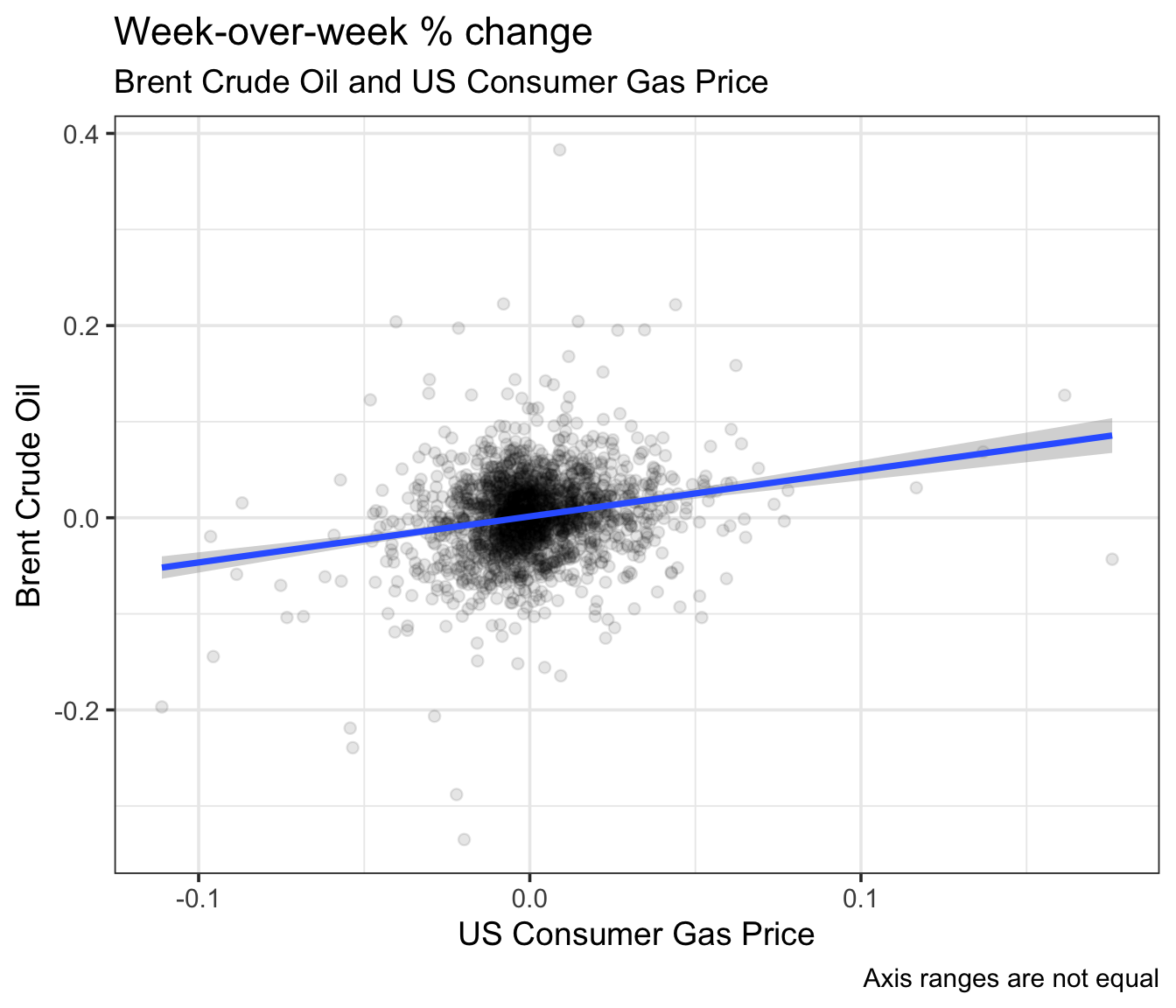
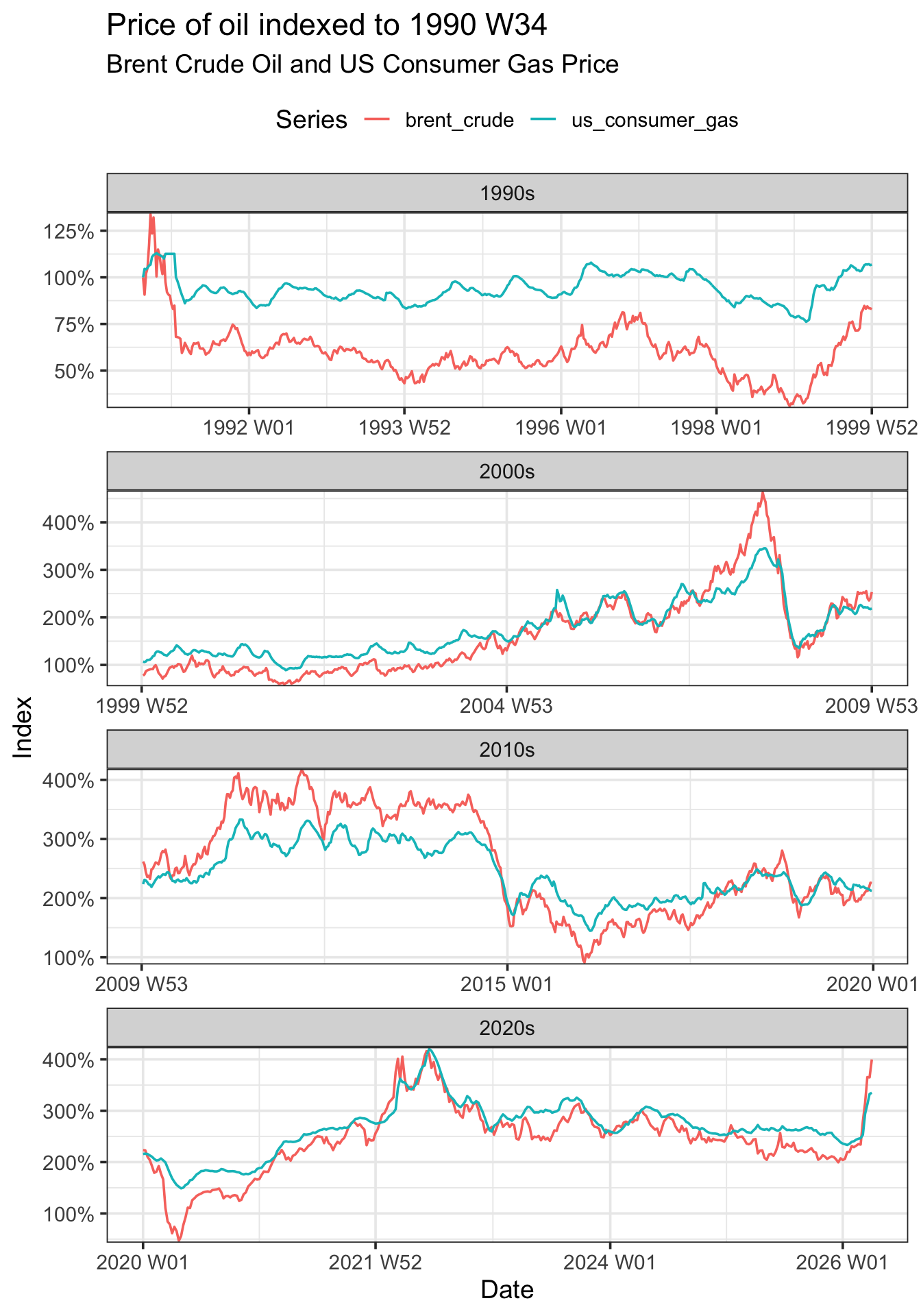
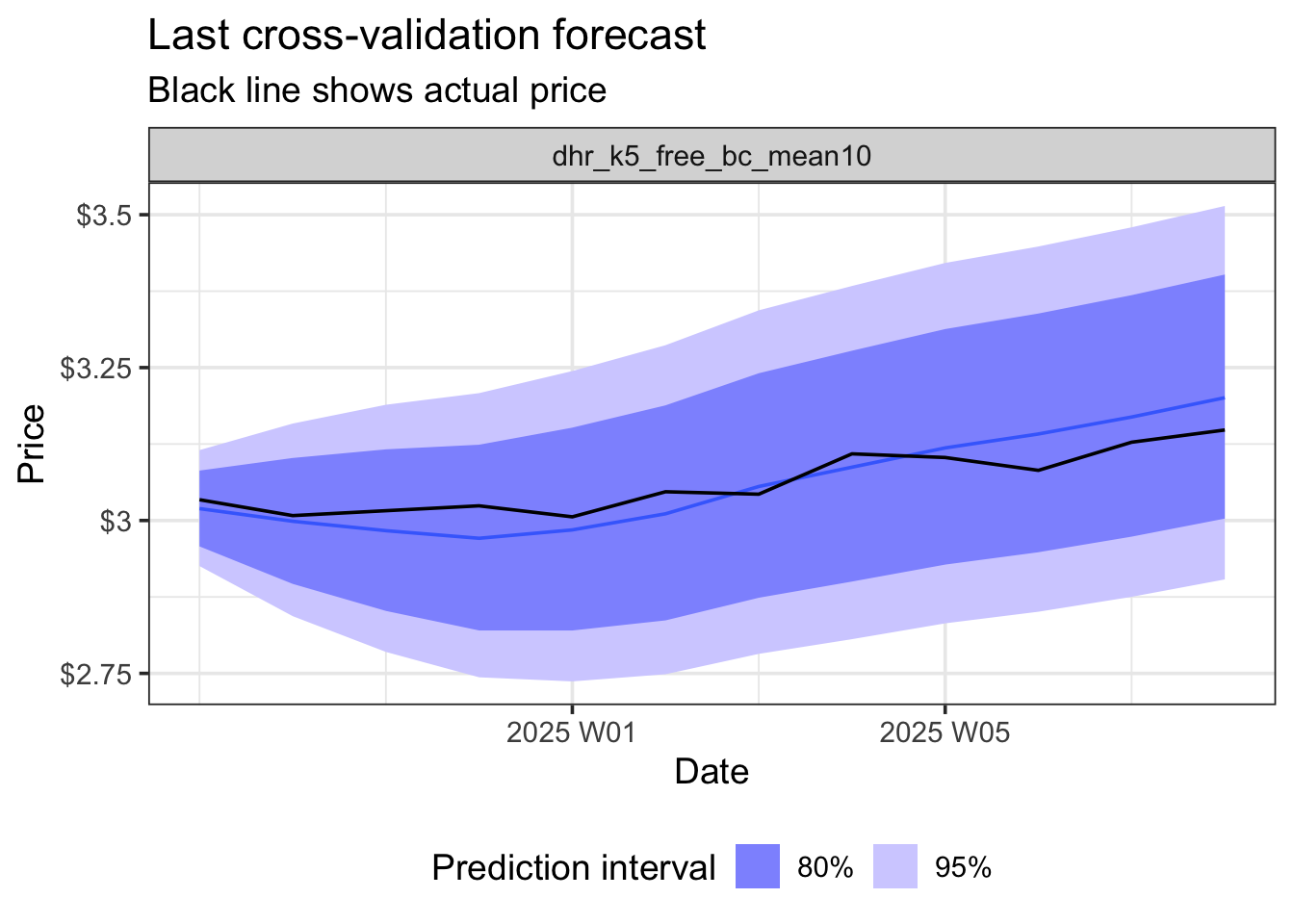
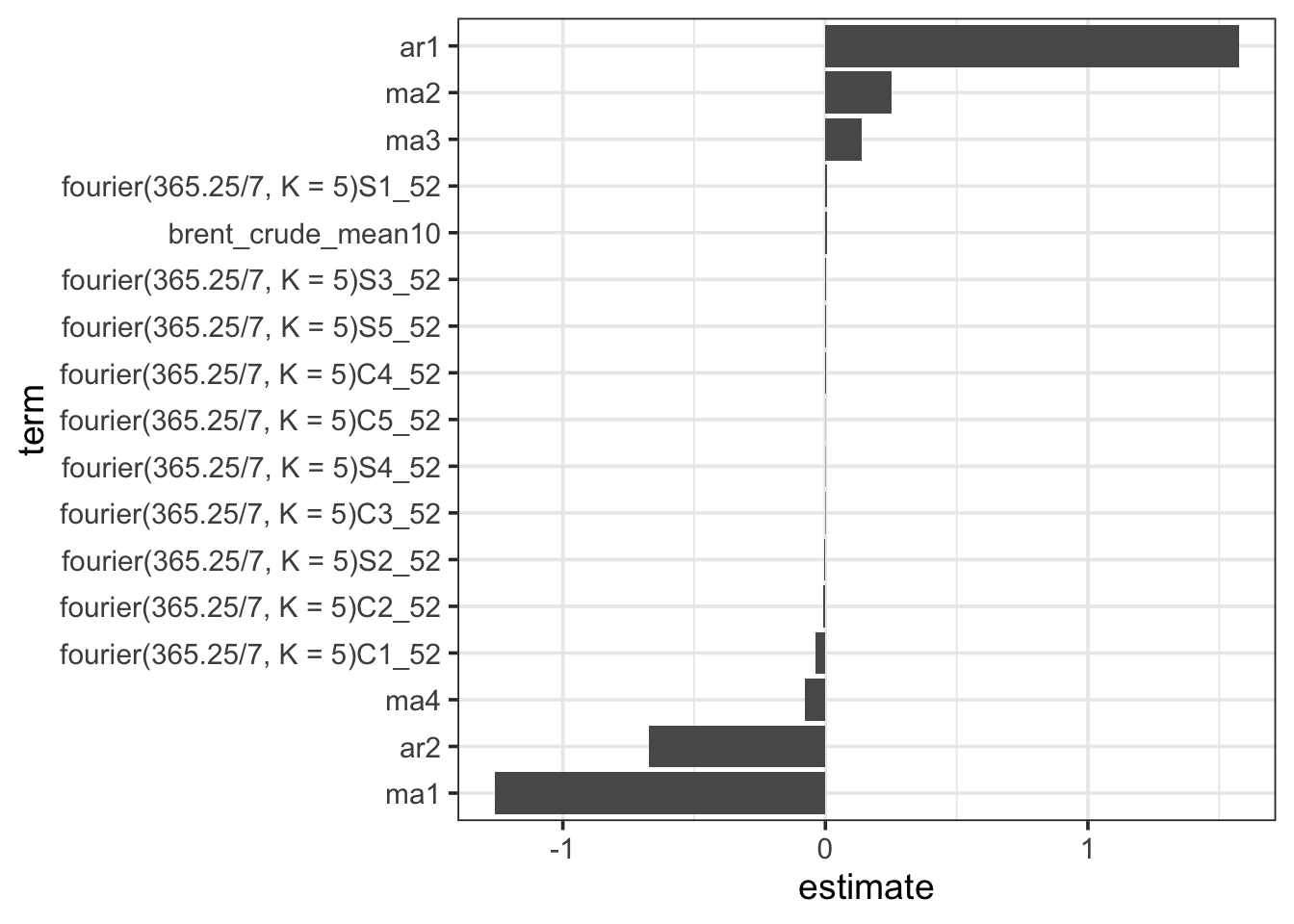
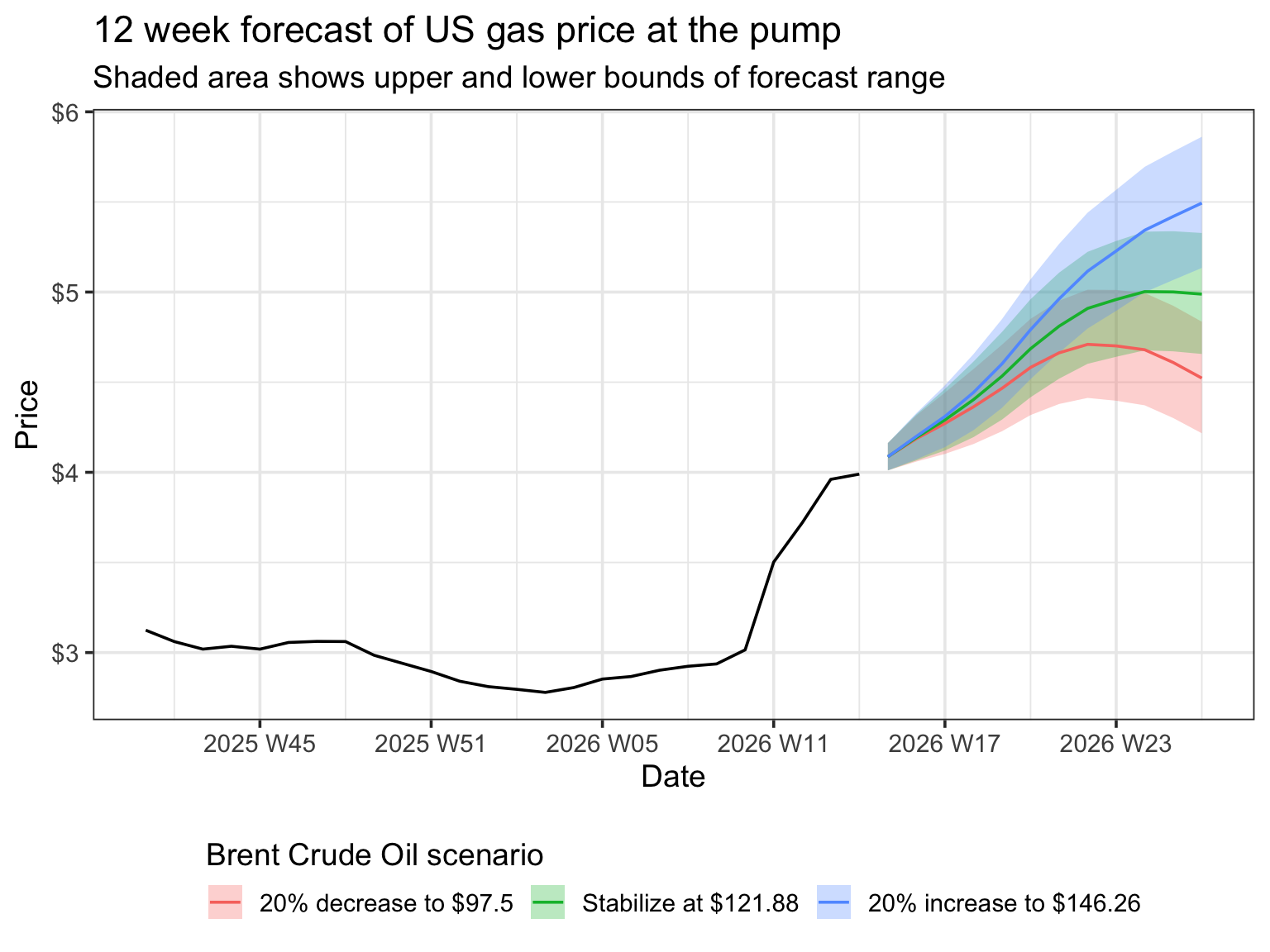
Rows: 8
Columns: 18
Key: .id, series [8]
$ .id <int> 1, 2, 3, 4, 5, 6, 7, 8
$ series <chr> "us_consumer_gas", "us_consumer_gas", "us_consumer_gas", "…
$ naive <model> [NAIVE], [NAIVE], [NAIVE], [NAIVE], [NAIVE], [NAIVE], [NAI…
$ dcmp <model> [STL decomposition model], [STL decomposition model], [S…
$ mean_16 <model> [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], …
$ mean_52 <model> [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], [MEAN], …
$ tslm_k1 <model> [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], …
$ tslm_k3 <model> [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], …
$ tslm_k5 <model> [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], …
$ tslm_k7 <model> [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], [TSLM], …
$ dhr_k1_pdq <model> [LM w/ ARIMA(2,1,2) errors], [LM w/ ARIMA(1,1,0) errors]…
$ dhr_k3_pdq <model> [LM w/ ARIMA(2,1,1) errors], [LM w/ ARIMA(0,1,1) errors]…
$ dhr_k5_pdq <model> [LM w/ ARIMA(1,1,0) errors], [LM w/ ARIMA(0,1,1) errors]…
$ dhr_k7_pdq <model> [LM w/ ARIMA(1,1,0) errors], [LM w/ ARIMA(0,1,1) errors]…
$ dhr_k1_free <model> [LM w/ ARIMA(4,1,1)(1,0,0)[52] errors], [LM w/ ARIMA(1,1…
$ dhr_k3_free <model> [LM w/ ARIMA(2,1,1)(1,0,0)[52] errors], [LM w/ ARIMA(0,1…
$ dhr_k5_free <model> [LM w/ ARIMA(1,1,0) errors], [LM w/ ARIMA(0,1,1) errors]…
$ dhr_k7_free <model> [LM w/ ARIMA(2,1,1)(1,0,0)[52] errors], [LM w/ ARIMA(0,1…